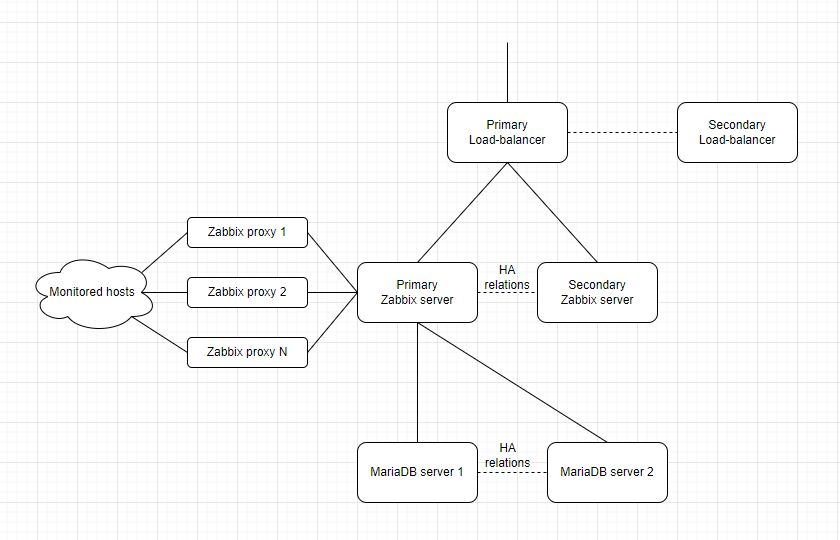
Let’s say, you decided to NOT use a great complex solution from SolarWinds, but still look for a great monitoring solution. In this case, Zabbix is your best friend. Its flexibility could be a great asset for the company, but it is still not the ideal solution. Here is a simple solution to how to build up a fault-tolerant Zabbix cluster.
What we would like to achieve: we would like to have a fault-tolerant front end (Zabbix server + Web UI), fault-tolerant backend (database cluster), and the ability to monitor thousands of hosts with hundreds of items/parameters at each, and we could set data gathering period to 1 min, to have a huge amount of historical and actual data. I tested this solution with a HIGH number of gathered parameters (more than 300k items queried every minute) and a HUGE database (~1Tb). Solution working fine, without any noticeable delays in queries. Should note: The efficiency of a solution depends on assigned resources and the configuration of servers – resource shortage and bad configuration will lead to degraded performance, glitches, and potential instability of the cluster.
The solution itself:
Front-end and Zabbix server = Nginx + Zabbix web UI + native Zabbix HA. (2 servers are enough).
Database cluster solution = MariaDB + Galera (I`m advising to use 3 or more database servers, but still working fine with 2 database servers. Notice: yep, subject of assigned resources and server configuration).
Zabbix proxy = dockerized Zabbix proxy (if you need to run custom scripts – you will need to rebuild the docker container). Notice: yep, also the subject of assigned resources and server configuration (and container configuration).
If you do this with the right resources and correct configuration you will get a great monitoring solution.